
This is the 5th chapter of the “Git – Simplified” course, in which we will go through Git from zero to hero. If you are just starting out with Git I highly recommend you to go to the 1st chapter in order to learn the basics of Git.
Table of Contents
Topics in this chapter
In this chapter we will go through the following topics:
- git stash
- Git revert
- Git squash
- Git reflog
🎤 Webinar recording (Hebrew)
You can find the presentation (ppt file) at this link. The recorded session of the webinar is live! you can view it here:
Git stash
Has it ever happened to you that you wanted to move to another branch but because you already edited some files it won’t allow you to move to the new branch?
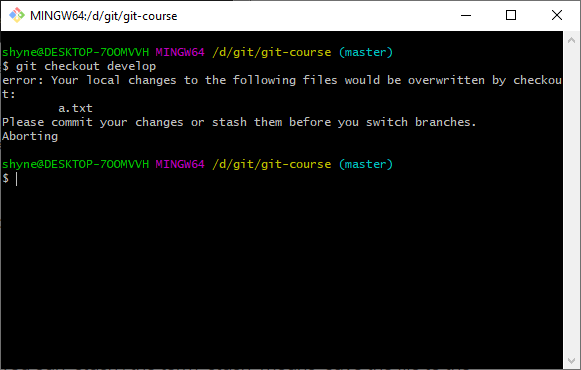
It usually happens when our file was edited on the target branch but on the source branch, the file was edited but not committed.
In this scenario, we only have two options:
- Either commit the file.
- Stash it.

If you don’t want to “commit” your file yet, you can “stash” it. The term “stash” means “save the file to the side, and when I need it I can bring it back from the stash”.
You can do it using the following command:
$ git stash a.txt # Stash our file to the side
Saved working directory and index state WIP on master: 2325133 first commit
$ git stash pop # Move the file back from the stash
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: a.txt
no changes added to commit (use "git add" and/or "git commit -a")
Dropped refs/stash@{0} (8656b40fd7b9050bca2a74c49455106d1e10edcd)Stashing files allows us to save them on the side, and bring them back whenever (any time) and wherever (to any branch) we want.
For example: move a file into a new branch or bring it back to our branch when we finished doing what we needed.
When we want to get the files back we can use this command:
git stash pop # Popup all of the files stores under the stashLet’s take a look at this example:
a.txt already modified on the “develop” branch, but was edited on the “master” branch and not committed. When we want to move to the “develop” branch, because our file was already edited on the “develop”, git does not know what to do. We use the git stash command to save the file to the side so we can later commit it again on the master branch.Git revert
The git revert allows us to “undo” commits, which means, if we have regretted a commit we have done, we can undo it.

The main advantages of “git revert” over “git reset” are the following:
- You can undo any commit you want without deleting any commits you had afterward. Using Git reset, it forces us to remove whole commits instead of a single one. For example, let’s take a look at this graph:
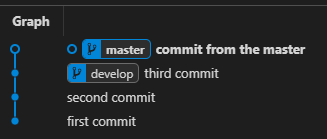
Let’s say we are on branch “develop”. If we want to remove only the “second commit”, using “git reset” we will lose all of the commits including the “third commit”. With “git revert” we will be able to “undo” only the second commit.
- It “reverts” a specific commit, by creating a new one with the “undone” changes. Your old commit will still exist, this is good for us it we also want to “undo” the “undo” later on (disable the revert).
The git revert command is very easy:
$ git revert COMMIT_HASH # Will revert any commit with the provided hashLet’s take a look at this example:
Git squash
The git squash is a feature implemented inside Git merge, which allows us to take all of the commits done on a specific branch, “squash” them into one commit, and merge them back to our current branch. It leaves our graph a lot clearer.

In my development projects, all features and bug fixes are done on another branch and are being “squashed” back. This makes my graph a lot clearer and leaves all of the “garbage” commits outside.
If you have a developer who “abuses” with a lot of commits, this will allow you to filter them out and only create one indicative commit.
The command goes as followed:
$ git merge --squash BRANCH_TO_MERGE # Merges the branch using squash to our current. branchI highly recommend you to squash your commits back when merging, especially when working in a large development team. This will make your graph look a lot more readable and easy to read:
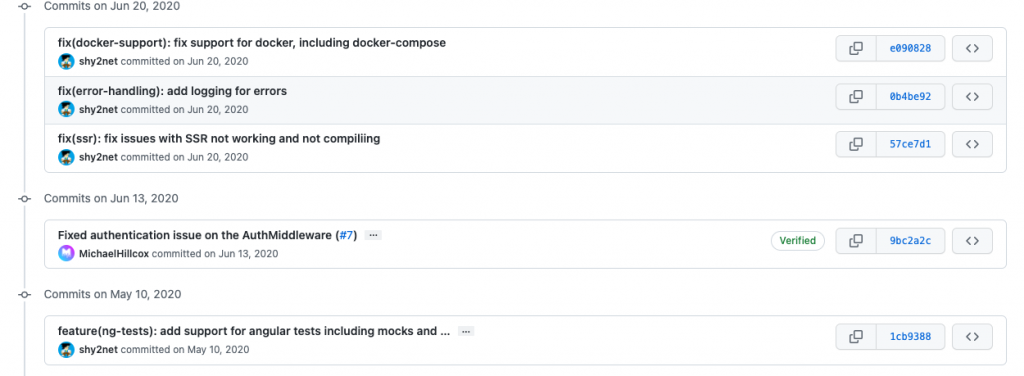
Let’s take a look at this example:
git merge --squash master all of the commits will be “squashed” into one and the master will only contain one commit with all of the changesGit reflog
The git reflog command allows us to see a log of all of the git commands we did. This allows us to see changes we did such as: Checking out branches, resetting, deleting branches, merging, and more.
Let’s see an example of the git reflog command output:
$ git reflog
...
32075e9 HEAD@{2}: checkout: moving from master to feature/auth
7975748 HEAD@{3}: checkout: moving from feature/auth to master
32075e9 HEAD@{4}: checkout: moving from master to feature/auth
7975748 HEAD@{5}: commit: add file b.txt
2325133 HEAD@{6}: checkout: moving from feature/auth to masterNot only allow us only to see the commands we did, but we can also move to the state of our HEAD in that specific commits using the git checkout command or even reset the state using git reset --hard REFLOG_HEAD .
Let’s take a look at this example:
git reset --hard, and then created two commits. Then we can undo that and return to the “second commit” state by finding the “reflog” hash we want to return to and hard resetting into thatTo Summarize
In this guide we learned about Git stash, revert, stash and reflog. These tools will help you through your “journey” with Git and can be very helpful in the future.
